Expermenting Deep Models for Text Classification
Text classification as an important task in natural lanugage understanding (NLP) has been widely studied over the last several decades. The task describes input as a document and output as the category of which the document belongs to. In literature, both supervised and unsupervised methods have been applied for text classification.
This blog only sets its scope on supervised learning methods. More specifically, it only focues on deep learning supervised methods that have gained great success in recent years. For knowing about latest advances of unsupervised methods in text classification, here is a recommended recently-published paper (Haj-Yahia, et al., 2019).
This blog amis to use three different deep leanring methods for text classification on three datasets. The code repository associated with this blog can be found here. Three datasets used in the blog are 5AbstractsGroup, SST-2 and reddit_jokes. These datasets are conditioned under license so you need to download them through their original sources.
The structure of the blog is organized as follows.
Table of Contents
- Datasets description
- BiLSTM and experiment
- BCN+ELMo and experiment
- BERT and experiment
- Experimental results
- Conclusion
1. Datasets description
Table 1 gives details of the three datasets that are used in the blog. As seen from the table, the three datasets are different in types, including topic, sentiment and joke. They are also different in size, ranging from 6k to 155k. The diverse features make it more robust for experimental comparions between different methods later on.

-
5AbstractsGroup is a topic-based datasets. It consists of 6246 examples. Indeed, this is not a big dataset for training a deep learning model. The examples are extracted from Web of Science and are a collection of academic papers with five different topics - business, artificial intelligence, sociology, transport and law. In this blog, I only use abstracts of these papers as training texts. The dataset is split into train/dev/test: 4996/624/626.
-
SST-2 refers to Standford Sentiment Treeback 2 and it is a famous dataset in sentiment analysis. It consists of short text sequences that are manually anotated in terms of their sentiment polarity, namely, positive (1) or negative (0). This dataset with 68220 examples is relatively larger than 5AbstractsGroup. The standard dataset from the official website contains a training set (67349 examples) and a development set (871 examples). I keep the split scenario and evaluate on the development set so as to compare state-of-the-art performance in parallel (check GLUE benchmark leaderboard).
-
reddit_jokes is a collection of English plaintext jokes scraped from Reddit. Originally, it has 195k examples and each joke is assigned a post score indicating the joke’s popularity or to say the extent of humor. I removed jokes with long texts and only keep those with words less than 50. Also, the title and body fields in the orignal datsets are combined to a single content field with <t/b> as separator. Because orginally the jokes are represented by a post score that is not suitable for text classification. I transformed the numeric scores into four categorical classes indicating four different levels of humor. The four classes are low, medium, high and crazy that are generated by setting up a score range. A joke that falls in a higher score range is assigned to a higher level of humor. After the preprocessing, 155027 examples are kept and subsequently split to train/dev/test: 124021/15502/15504.
2. BiLSTM and experiment
This section presents a popular recurrent nerual network (RNN) method - Bidirectional Long short-term Memory (BiLSTM) for classification on the three datasets. LSTM (Hochreiter, et al., 1997) is memory-based unit in RNN, which helps to summarize the state of previous tokens in a sequence given a token at time step
. For example, Figure 1 (a) shows the process of LSTM in RNN (picture credit: Zhang, et al., 2018). At time step
, a token
can be represented by a vector
through an embedding layer. The LSTM unit takes
with previous
hidden states as input to output a new hidden state that summarizes important information of the sequence so far (from time step 0 to
). It summarizes important information by remembering or forgetting information through the recurrent process. It ends up with a vector that summarizes the whole sequence at the last time step. The last vector is normally used as representation input of subsequent feedforward layers for generating probabilities distribution over all classes. Unlike LSTM only summarizing information in one direction from left to right, BiLSTM sees context of a token at time step
in both left-to-right and right-to-left directions (as you can see from Figure 1 (b)). To better understand how LSTM/BiLSTM works, one point worth bearing in mind is that, in the recurrent process, all stuff are represented by vectors so that complicated mathematic functions can be leveraged on.
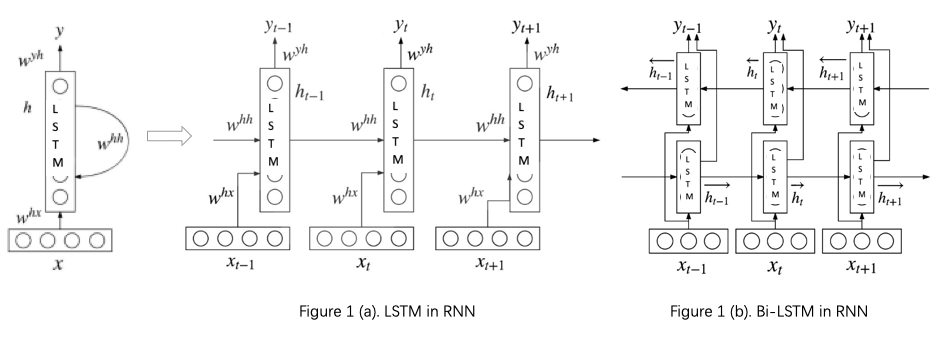
If you are not so familar with LSTM and avid reading learner, here is a recommended learning route for LSTM.
-
Know basics of neural network including computational graphs, perceptrons, training criterion, and activication functions, gradient descent optimazition methods and back propagation, etc.
-
Definitely have a look at colah’s blog on understanding LSTM networks where you find excitingly how mathematics leverage “memory” on neural network
-
Next, it’s recommended to go deeper into implementation level. Although there are many open souce libraries that you can rely on to implement LSTM in real-world applications. For me, I am interested in designing deep learning models for NLP tasks, so AllenNLP is highly recommended if you have the same interest. With AllenNLP, you will easily understand how matrix is transformed in a neural network model (I recommend you to do this through breakpoint debugging in IDE like PyCharm) . Not only this benefit, this library is beautifully designed for NLP researchers and enables you to customize a model flexiblely like lego stacking.
-
Paper reading for research interests: Zhang, et al., 2018; Young, Tom, et al., 2018; Zhou, Peng, et al., 2016; Yang, Zichao, et al., 2016; Zhou, Chunting, et al., 2015 etc.
Back to the blog’s focus, the following graph presents the architecture of a simple BiLSTM model that are trained on the three datasets. It embeds the text first (through glove.6B.100d) and then encode it with a BiLSTM Encoder, and then pass the result through a feedforward network, the output is used as the scores for each label. The model is implemented with reference to AllenNLP’s built-in basic classifier.
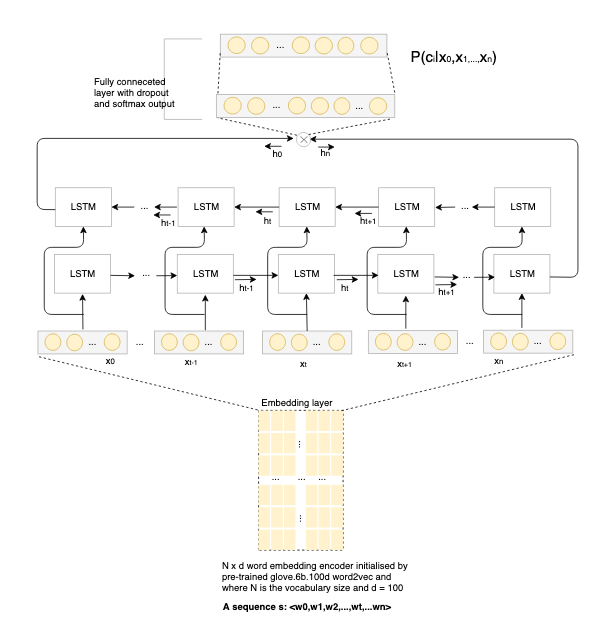
In terms of experimental setup, examples are processed in batch of 64 and trained in 40 epochs with patience=5 for early stopping based on accuracy evaluation on development/validation set. Adam with learning rate 0.001 is used as optimizer and cross entropy is used as objective function. The experiment is run on a single nvidia RTX 2060 6GB GPU. With this GPU configuration and simplicity of the BiLSTM model, any one of the three experiments for each dataset is run no more than 3 minutes. The evaluation is reported on the predictions for test set except that SST is evaluated on development set.
3. BCN+ELMo and experiment
McCann, Bryan, et al. 2017 first implemented BCN (Biattentive Classification Network ) integrated with CoVe (Context Vectors) on many classification datasets. More recently, Peters, Matthew E., et al. 2018 in his ELMo (Em-beddings from Language Models) paper integrated with BCN achieves state-of-the-art (SOTA) performance in many language understanding tasks including classification task. As you can see from the leaderboard, the BCN+ELMo model achieved SOTA performance on SST-5 fine-grained sentiment classification task.
Going deep into the model is beyond the scope of the blog. To know its internals, have a look at my previous blog that guides you to understand BCN+ELMo. For implementation, the model is designed based on a condensed version of the original one in AllenNLP. The original model is bigger where d is 300 (see the following graph), whereas I adapt it to be 100. In addition, the glove embedding I used is 6B.100d instead of 840B.300d as in the original. I change the model to be a smaller one in order to well suit my local hardware’s capacity. If hardware like GPU or TPU are guaranteed, it is suggested to try the original that may give better performance. Basically, I adapted the BCN+ELMo structure to be as shown in the following graph. As presented in ELMo paper, there are four pre-trained ELMo models different in size. I used the original one with 93.6 millions. Check here to know different-size pre-trained ELMo models.
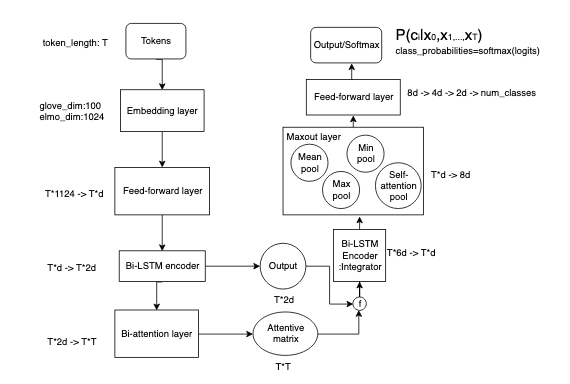
Regarding the experimental setup, most of hyper parameters like learning rate, optimizer and number of epochs are kept as the same as in BiLSTM experiment. The only difference is that the batch size is changed from 64 to 16. Still, this is because the CUDA out-of-memory issue can be avoided if giving a relatively small batch size. Due to more complicated architecture of BCN+ELMo, the training time is a lot longer than BiLSTM. It is estimated that training BCN+ELMo on any of the three datasets is more than 30 minutes.
4. BERT and experiment
BERT (Bidirectional Encoder Representations from Transformers) was proposed by Devlin, Jacob, et al., 2019 that has gained great attention in NLP community due to BERT’s powerful performance in many sentence-level language tasks. BERT is similar to ELMo for building contextual representations. However, BERT is a Transformer-based architecture that only applies self-attention mechanism to pre-train a language model (Attention is all you need). Unlike ELMo that is trained on a LSTM-based Bi-LM (Bidirectional Language Model), BERT is trained with a different language modeling objective called masked language modeling. There are two different-size BERT pre-trained models in publication. The following table (credit: Munikar, et al., 2019) shows BERT_base VS. BERT_large. In experiment, I used the base version.

If you are not so familar with BERT and avid reading learner, here is a recommended learning route for BERT.
-
Get a good understanding of Google’s Transformer (Vaswani, Ashish, et al., 2017) via the The Illustrated Transformer blog by Jay Alammar. This blog did a great job in explaining Transformer with nice visualization. Definitely worth checking if you want to know what is really going on behind Transformer.
-
Next, I recommend Chris McCormick’s tutorials on BERT embedding and Fine-Tuning. The tutorials bring you to understand BERT at implementation level. I like the tutorials because the author not only presents the code but also well explain why we need that code in details step by step.
-
Go check 🤗 Transformers (Wolf, Thomas, et al., 2019) developed by HuggingFace. It is nowadays a popular open source library that provides state-of-the-art general-purpose architectures (BERT, GPT-2, etc.) for Natural Language Understanding (NLU) and Natural Language Generation (NLG). You may notice a cute emoji 🤗 before the name that distinguishes it from the commonly-known google Transformer. So don’t be confused with the name. Actually, the library changed its name three times this year, from
pytorch-pretrained-bert,pytorch-transformers, to current🤗 Transformers. From the name evolution, we can see it was originally developed for BERT implementation in PyTorch. Now it is expanded to support other state-of-the-art architectures (not just BERT) implemented in both Pytorch and TensorFlow 2.0. Hacking this library helps know how to adapt state-of-the-art models to your problem domain. -
At this stage, you may have questions like why BERT works so well or what future work can be done in the area. I suggest you to have further paper reading. Since BERT came up, many follow-up research has been done. You can find a summary of relevant papers here.
In the experiment of using BERT to do classification, I adapted the BertForSequenceClassification model in 🤗 Transformers to fine tune on my prepared three datasets. The train batch size is set to be 8 (you may change it to a proper number compatible with your hardware) and number of training epochs is 3. Other hyper parameters keep the same as default in 🤗 Transformers. Due to the fine-tunning process requiring only a small number of epochs in BERT, it doesn’t take long time to finish training on the three datasets. In next section, I will report experimental results showing how different models influence performance given different dataset domains.
5. Experimental results
After training BiLSTM, BCN+ELMo, BERT on 5AbstractsGroup, SST2, and reddit_jokes, evaluation is conducted on test set of 5AbstractsGroup and reddit_jokes, and development set of SST2. Evaluation metrics chosen for performance report include precision, recall, F1 and Accuracy. Table 2 gives exact these metrics’ scores of the three models on 5AbstractsGroup, SST2, and redditjokes.

Taking a look at performance of the three models on redditjokes, we found the results are poor and not reliable. I doute this is an example of wrongly defining a machien learning problem. I explain the issue with such a possible reason. The ground truth of redditjokes is orignally the post scores on Reddit. These scores only represent the public’s opinions on a joke. This kind of subjective opinions break groundtruth so such a task is hard for machines to find patterns between classes. A lesson from this task: enabling machine the ability in identifying the level of humor given a plaintext human-written joke is what François tweeted: “For all the progress made, it seems like almost all important questions in AI remain unanswered. Many have not even been properly asked yet”. Anyway, I think how to enable machine with humor remains an interesting and serious research question in the future. Due to the mistake here, I will ignore discussing performance on redditjokes in the following part.
Now, if we have a look at the evaluation scores of BiLSTM, BCN+ELMo, BERT on 5AbstractsGroup, and SST2, we found BCN+ELMo improves the performance to a large extent in comparison to BiLSTM. This is likely due to the application of bi-attention mechanism in BCN+ELMo. Although BERT achieves the best performance among the three methods on both datasets, it only improves the performance slightly on 5AbstractsGroup compared to BCN+ELMo. However, BERT hits good scores in all metrics on SST2, with 0.9268 and 0.9266 in F1 and accuracy respectively. These scores are also competitive with state-of-the-art accuracy in GLUE benchmarking lederboard. The experiment with BERT only applies the small-version model and it is expected to further improve accuracy if applying the large-version model or further tunning hyper-parameters. It is also an interesting future work to compare performance by appling other state-of-the-art models such as XLNet, RoBERTa (that are easily accessible via the 🤗 Transformers library). Overall, as the experimental results revealed, BERT has an advantage over the other two methods in the classifcation tasks. More specific evaluation report on each class of each dataset using each method can be accessed here.
6. Conclusion
This blog presents three commonly-practised deep methods for text classification, namely, BiLSTM, BCN+ELMo, and BERT. Three datasets are given to test the performance of the three methods. Although methods like BERT nowadays have achieved a very good performance not only in text classification but also other language understanding tasks, many research problems still remain to be tackled in the future. For example, a recent hot topic around AI is GreenAI (Strubell, Emma, et al., 2019; Roy Schwartz, et al., 2019; Sanh, Victor, et al., 2019). GreenAI emphazies future research should not only blindly pursue accuracy but also care about carbon footprint produced by training big deep models. As the tweet puts: “The future is not about bigger models, it’s about bigger ideas”.
For all the progress made, it seems like almost all important questions in AI remain unanswered. Many have not even been properly asked yet.
— François Chollet (@fchollet) March 2, 2017
Souce code: github repository
If you have any doubts or any my mistakes you found in the blog, send me an email via wangcongcongcc@gmail.com or you are welcome to talk with me about any NLP relevant questions through my Twitter account.